The Gen AI Cooling Crisis: How Hyperscalers Are Rethinking Thermal Design
The generative AI revolution is creating an unprecedented thermal crisis in datacenters. As GPU clusters scale to support large language models and AI training workloads, traditional cooling approaches are hitting fundamental limits. NVIDIA's H100 dissipates 700W, and the upcoming Blackwell architecture pushes past 1000W per chip. When you pack thousands of these into a single facility, you're looking at cooling challenges that would have seemed impossible just five years ago. This article examines how hyperscalers are responding and what it means for power electronics engineers.
The Scale of the AI Thermal Challenge
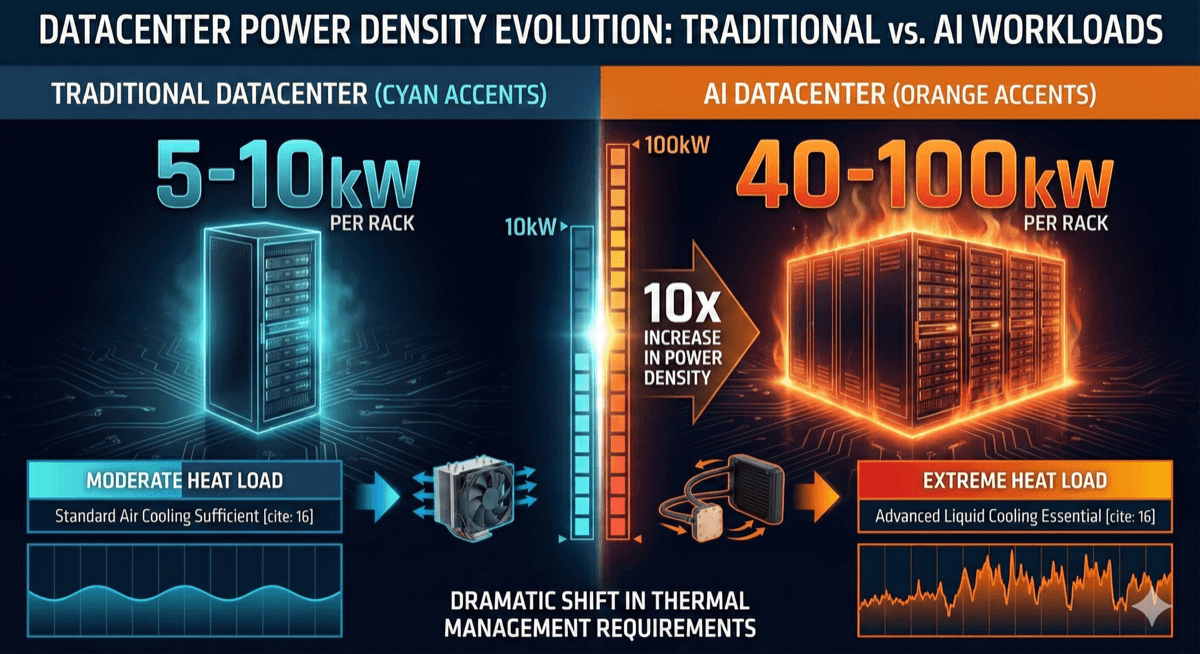
To understand the magnitude of the cooling crisis, consider the numbers. A single NVIDIA DGX H100 system—containing 8 H100 GPUs—consumes up to 10.2kW. A typical AI training cluster might contain 1,000 such nodes, translating to over 10MW of IT load in a single facility. Add in networking, storage, and cooling overhead, and total facility power can exceed 50MW.
Traditional datacenters were designed for 5-10kW per rack. AI facilities are now pushing 40-100kW per rack, with some experimental deployments exceeding 150kW. This 10-20x increase in power density requires completely rethinking every aspect of thermal management, from chip-level cooling to facility design.
The power consumption of AI training is growing exponentially. Training GPT-3 in 2020 required approximately 1,300 MWh. GPT-4's training consumed an estimated 50,000 MWh. As models scale toward AGI-level capabilities, power requirements are projected to reach into the gigawatt range. The thermal implications are staggering.
Why Traditional Cooling Fails
Air cooling, the backbone of datacenter thermal management for decades, simply cannot scale to AI workloads. The fundamental physics are limiting:
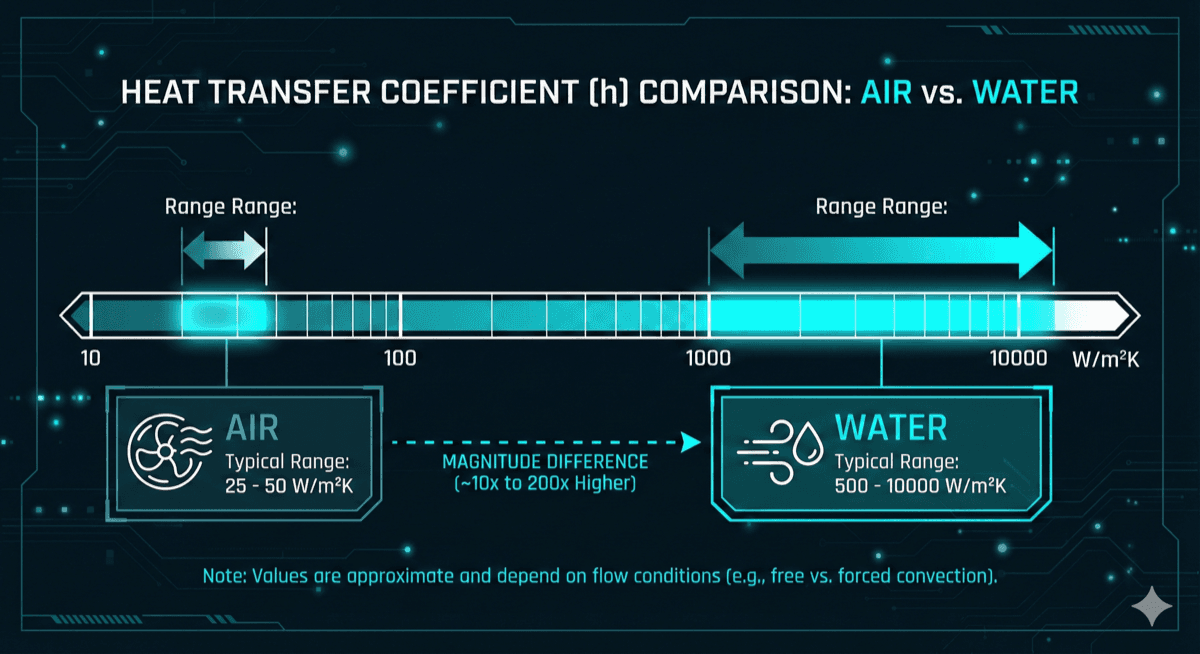
Heat Transfer Coefficient: Air has a convective heat transfer coefficient of roughly 25-50 W/m²K under forced convection. Water achieves 500-10,000 W/m²K. This order-of-magnitude difference becomes critical at high heat fluxes.
Power Density Limits: Air cooling can effectively handle 10-15kW per rack. Beyond this, air velocity requirements become impractical—you'd need hurricane-force winds to move enough air. The result is thermal throttling, reduced performance, and reliability concerns.
Infrastructure Burden: High-density air-cooled facilities require massive CRAH units, elevated floors with deep plenums, and enormous chillers. The mechanical infrastructure can exceed 40% of total facility cost and consume 30-40% of total power (PUE of 1.3-1.4).
Geographic Constraints: Air-cooled facilities perform best in cold climates where free cooling is available. This limits siting options and often places datacenters far from renewable energy sources.
The hyperscalers recognized these limitations early and have been investing heavily in liquid cooling infrastructure. Microsoft, Google, and Meta have all announced major liquid cooling deployments, with some facilities transitioning to 100% liquid-cooled IT loads.
Liquid Cooling Architectures for AI
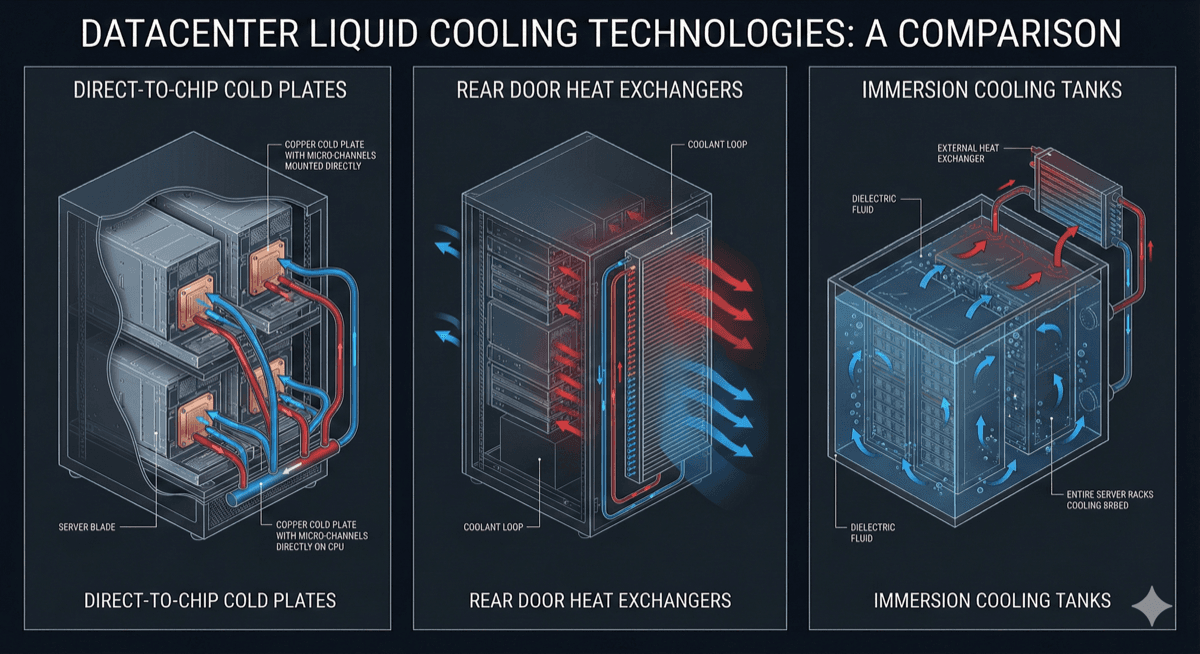
Three liquid cooling architectures are emerging as standards for AI infrastructure:
Direct-to-Chip (Cold Plate) Cooling: Cold plates mount directly to GPU packages, providing the shortest thermal path and lowest thermal resistance. Modern cold plate designs achieve thermal resistances below 0.02°C/W, enabling 1000W+ GPU cooling with manageable junction temperatures. This approach is used in NVIDIA's reference designs and most OEM server platforms.
Rear Door Heat Exchangers (RDHX): For transitional deployments, RDHX units mount to the back of standard racks and remove heat from exhaust air using chilled water. While limited to about 50kW per rack, RDHX enables liquid cooling benefits without modifying servers. It's a pragmatic first step for facilities transitioning from air cooling.
Immersion Cooling: Single-phase or two-phase immersion submerges servers in dielectric fluid. This approach can handle extreme power densities (250kW+ per tank) and eliminates fans entirely. However, it requires purpose-built hardware and significant operational changes. Companies like Submer and GRC are seeing growing adoption for AI-specific deployments.
The trend is clearly toward direct-to-chip cooling as the primary heat removal path, with facility-level water infrastructure to transport heat outside. Warm water cooling (inlet temperatures of 35-45°C) is gaining favor because it enables free cooling in most climates and reduces chiller requirements.
Hyperscaler Innovations
The major cloud providers are driving innovation in AI thermal management:
Microsoft: Deployed liquid cooling across Azure AI infrastructure, with cold plates handling GPU heat and facility-level heat rejection to outside air. Their Project Natick explored underwater datacenters, leveraging ocean water for cooling.
Google: Pioneered the use of ML to optimize datacenter cooling, reducing cooling energy by 40%. Their TPU clusters use custom cold plate designs optimized for their proprietary chips.
Meta: Building AI-optimized datacenters from the ground up, with 100% liquid cooling capability and on-site renewable energy. Their Taylorville, Illinois facility is purpose-built for AI training.
AWS: Graviton processors are designed for thermal efficiency. While AWS is less public about cooling innovations, their data suggests significant investment in custom cooling solutions for Trainium and Inferentia chips.
NVIDIA: The DGX SuperPOD reference architecture includes complete liquid cooling infrastructure specifications, with partnerships with cooling vendors to ensure compatibility.
These hyperscalers are spending billions on cooling infrastructure. For smaller players and enterprises deploying AI workloads, the challenge is adapting these innovations to more modest scales while maintaining efficiency.
Implications for Power Electronics
The AI cooling crisis creates significant opportunities and challenges for power electronics engineers:
Higher Power PDUs: Traditional 20-30kW rack PDUs are inadequate. AI racks need 60-100kW PDUs with sophisticated monitoring and protection. Bus bar designs must handle 400-600A continuous current while maintaining thermal margins.
Coolant Distribution Units (CDUs): These systems—essentially heat exchangers that transfer heat from facility water to server coolant loops—are becoming standard infrastructure. They require precise flow control, leak detection, and redundancy features.
Power Conversion Efficiency: When you're dissipating 50MW of IT load, every percentage point of efficiency matters. Efficiency improvements in UPS systems, rectifiers, and voltage regulators directly reduce cooling requirements.
Liquid-Cooled Power Electronics: Power supplies themselves are moving to liquid cooling to handle increased thermal density. Server PSUs with integrated cold plates are becoming common in high-density deployments.
For engineers, this means developing expertise in liquid cooling systems, high-current bus bar design, and thermal management at unprecedented power densities. The skills developed for EV charging and grid-scale energy storage translate well to datacenter applications.

The Path Forward
The Gen AI boom shows no signs of slowing. OpenAI, Anthropic, Google, and others continue to scale model sizes, requiring ever-larger training clusters. The thermal challenges will only intensify.
Several trends are emerging:
Facility Design Evolution: Purpose-built AI datacenters are replacing retrofitted facilities. These include liquid cooling as primary infrastructure, not an afterthought.
Edge AI and Inference: While training requires massive centralized clusters, inference is moving to the edge. This creates thermal challenges in constrained environments—think of cooling an H100-class GPU in an autonomous vehicle or industrial robot.
Custom Silicon: As hyperscalers develop custom AI chips (Google TPU, AWS Trainium, Tesla Dojo), they're co-designing silicon and cooling solutions for optimal efficiency.
Sustainability Pressure: With AI consuming an increasing share of global electricity, there's intense pressure to improve efficiency. Liquid cooling enables PUE approaching 1.1, compared to 1.3-1.4 for air-cooled facilities.
For power electronics engineers, the message is clear: develop liquid cooling expertise now. The transition from air to liquid is accelerating, and the engineers who understand both thermal physics and power systems will be in high demand.